BedrockとPineconeを使って資料特化型AIチャットを作成してみた
BedrockとPineconeを使って社内資料を回答してくれるAIチャットを作成した

※2026年4月現在、本記事に記載されているLambdaのコードはLLMモデルがサポート外になったため動作しません。進化のスピードが速すぎる…
近年、サプライチェーンリスクが社会全体で認識されるようになり、取引先からも「御社はセキュリティ関連のルールを定めているか」と問い合わせを受けることが増えました。セキュリティ担当としてきちんとルールを作成してきましたが、いくら情シスがルールに従って行動していても、肝心の従業員がルールを知り、守ってくれないと意味がありません。
そのため、会社にある様々なセキュリティ関連の資料を従業員に読んでもらいたいのですが、社内のポータルに掲載しても正直誰も読んでくれません(T_T)。そこで、Pマーク保持企業では年1回の実施が義務付けられているeラーニングの際に、今年はセキュリティ関連の資料を読みながら受講してもらおうと思いつきました。
しかし、セキュリティ関連の資料は複数あり、これを一つ一つ開いて関連する内容を調べて…というのは面倒で仕方ないですよね。僕だってやりたくありません。そんな僕が最近ひじょうにお世話になっているのが、Google Workspaceの「NotebookLM」です。言ってみれば「ソースを限定させたChatGPT」のようなもので、Googleドライブ上のファイルやWebサイトのURL、ローカルのファイルをアップロードして、それをソース(情報源)としたチャットボットが作れます。これの何が便利かというと、社内資料の検索・調査が爆速になること。法務・総務・情報システム部門にとっては本当にありがたいツールです。
しかし、個人で便利に使っているこのNotebookLMを、従業員全体に共有しようとすると技術的な課題がありました。 企業用のGoogle Workspaceは個人向けと異なり、作ったNotebookLMを組織外の人と共有することが制限されています。また、従業員の中にはGoogleアカウントを持っていない人もいるため、全員が利用できるわけではありません。Microsoftにもよく似た「Copilot Notebook」というサービスがありますが、これを利用するには1ユーザ月額4,000円ほどのCopilotライセンスが必要になり、とてもそんな予算は出せません。
「社内資料をソースとしたAIチャットを、不特定多数に共有するにはどうすればよいか…」と、これもGeminiに相談したところw、要望を満たしてくれるアイディアを教えてくれました。Geminiが提案してくれたのは、
『PineconeBedrockを自分で組み合わせて、APIでアクセスする』
という意欲的なアイディア。AWS資格を持っているし、この辺りを実際に触ることは意義があると感じました。何よりこの方法なら費用を抑えつつ、GoogleやMicrosoftのアカウントを持っていない人に対しても、アクセスを制限した状態で資料特化型AIチャットを提供することができます。今日はその方法を解説します。 インフラ構成図はこんな感じになります。
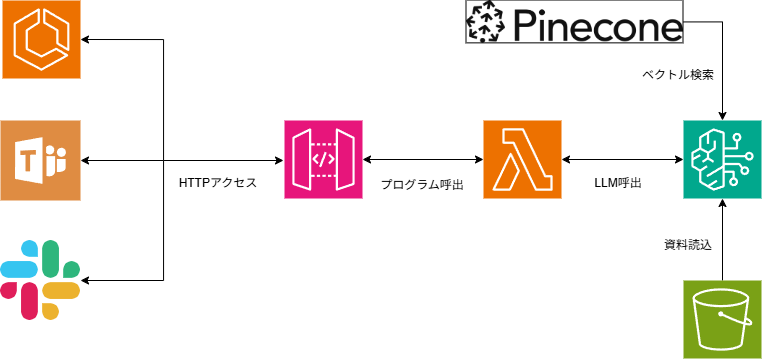
(1) S3に社内資料をアップロードする
見出しの通りです。PDFやテキストファイルなど、文字列として読み込めるフォーマットでS3にファイルをアップロードしてください。アップロード後、ファイルの「S3 URI」(s3://…)をメモしておいてください。
ポイント: 後続の Bedrock ナレッジベースで利用するため、必ず us-east-1 (バージニア北部) リージョンにバケットを作成します。
(2) Pineconeを準備する
まず前提として、Pineconeとは一言でいうと、「言葉の『意味』を保存・検索することに特化した、AI専用の知識倉庫」です。 普通のデータベース(Excelなど)は「キーワード」が完全一致しないと探せませんが、Pineconeのような 「ベクトルデータベース」 は、言葉を「数値の座標」に変換して保存します。
- 普通の検索: 「セキュリティ」で検索 → 「セキュリティ」という文字がある資料だけヒット。
- Pinecone(ベクトル検索): 「セキュリティ」で検索 → 「防御」「機密性」「脆弱性」など、意味が近い言葉が含まれる資料もヒット。
ここで少しだけ用語の整理です。今回の主役の一つである LLM(Large Language Model:大規模言語モデル) とは、膨大なテキストデータを学習し、人間のように自然な文章を生成できる「AIの脳」そのもののことです。 Amazon Bedrock は、この強力な LLM(脳)を安全に、そして簡単に利用できる AWS のサービスです。しかし、LLM 自身が学習した一般知識だけでは、会社固有のルールに基づいた回答はできません。
そこで、”Bedrock が S3 の資料を読み取ってベクトル化(数値化)し、その「記憶」を Pinecone という外部の専用データベースに保管しておく”仕組みを作ります。こうすることで、AI が質問を受けた際に Pinecone から関連する資料を探し出し、最新の社内データに基づいた正確な回答が可能になるのです。 加えて、LLM の知識は「学習を終えた時点」で止まってしまいますが、S3 + Pinecone の組み合わせなら、資料を更新して「同期」ボタンを押すだけで AI の知識をいつでも最新に保てます。
実は AWS 自身にもベクトルデータを保存するサービスはあるのですが、最低維持費が月額数万円〜とたいへんお高いため、今回は無料で使い始められてセットアップも簡単な Pinecone を外部ストレージとして採用しました。 それではPineconeを準備しましょう。
- 新規アカウントを作成します。
- インデックスを作成します。インデックス作成画面では、以下の値を正確に入力する必要があります。
- Index Name: 任意の名前で OK です(例: bedrock-knowledge-base)。
- Dimensions(次元数): 1024 を入力します。
- ここが最重要です。後々設定するBedrockで使用する「Titan Text Embeddings v2」の標準的な次元数が 1024 なので、これと一致させる必要があります。1024という数字は、AIが言葉の意味をどれだけ細かく数値化するかを決める『解像度』のようなものです。Titan Text v2 の場合、この解像度が 1024 個の数字の並び(次元)で表現されるため、受け皿となる Pinecone 側も同じ数だけ穴を開けて待っていなければいけません。
- Metric(距離の測定方法): Cosine を選択します。
- AI が「言葉の意味の近さ」を計算するための計算式の設定です。Titan モデルには Cosine(コサイン類似度)が推奨されています。
- Cloud Provider: AWS を選択します。
- Bedrock と同じ AWS 基盤上に構築することで、通信の遅延(レイテンシ)を最小限に抑えられます。
- Region: us-east-1 (N. Virginia) を選択します。
- S3 や Bedrock を構築したリージョンに合わせるのが鉄則です。
- Capacity Mode: Serverless を選択します。
このあとAPIキーが表示されますが、一度しか表示されないので、確実に保存しておきましょう。
(3) Secrets Manager を準備する
- us-east-1 (バージニア北部) リージョンに作成します。
- シークレットマネージャーにキー名:apiKey として、(2)で取得した Pinecone の APIキーを保存します。
- Bedrock は、このシークレットの中身が
{"apiKey": "xxxxxx"}という形式になっている前提で読みに行くため、キー名は必ず “apiKey” (Kは大文字) にする必要があります。
- Bedrock は、このシークレットの中身が
- 暗号化キーは
aws/secretsmanagerを選択します。
ところで、「パラメータストアの SecureString じゃダメなの? シークレットマネージャーは少額とはいえ費用が発生するのに」と疑問を持つかもしれません。これは、後述の Bedrock の設定でベクトルデータベースに Pinecone を選択する際、認証情報として「シークレットマネージャーの ARN」を指定することが必須要件になっているためです。
(4) Bedrockを準備する
ここまでバラバラに用意した部品を一つにまとめ、AIが社内資料を読み解ける状態(ナレッジベース)を作ります。
Bedrock の「ナレッジベース」は、RAG(検索拡張生成)の司令塔です。
- S3 から資料を読み取る
- 内容をベクトル化して Pinecone に保存・検索する
- 質問に対して適切な回答を生成する
これらの一連の流れを、コードを書かずにマネージドで実現してくれる強力な機能です。
作業をする前に、デフォルトでは後で使用するLLM(Claude 3 Haiku)は無効になっているため、左メニューの 『モデルアクセス (Model access)』 から使用をリクエストして有効にしておく必要があります。
- AWS コンソールの Amazon Bedrock 画面へ行き、左メニューから「ナレッジベース」を選択して「ナレッジベースを作成」をクリックします。
- データソースとして、手順(1)で作成した S3 バケット を指定します。
- チャンキング戦略(文章の区切り方)は、まずは「デフォルト」で OK です。
- 埋め込みモデルの選択。ここでは
Titan Text Embeddings v2を選択します。- 手順(2)の Pinecone 作成時に設定した次元数「1024」は、この Titan v2 モデルの出力に合わせたものです。ここが一致していないとエラーになります。
- ベクトルストアの選択(Pinecone の指定)
- 「作成したベクトルストアを選択」 を選びます。プルダウンから Pinecone を選択し、以下の情報を入力します:
- ConnectionString: Pinecone のインデックス詳細画面にある「Host」の URL。
- CredentialsSecretArn: 手順(3)で作成した Secrets Manager の ARN。
- 各フィールド名:
text(テキスト用)やmetadata(メタデータ用)など、Pinecone の設定に合わせたフィールド名を指定します。
- 「作成したベクトルストアを選択」 を選びます。プルダウンから Pinecone を選択し、以下の情報を入力します:
- モデルの選択(回答の生成役)。ナレッジベースの「テスト」や、後の Lambda で使用するモデルとして
Claude 3 Haikuを推奨します。- なぜ Haiku なのか?: Bedrockには様々なLLMが用意されていますが、使うモデルによって費用が変わります。Haikuは Claude 3 ファミリーの中で最も高速かつ安価でありながら、今回のような社内資料の要約や回答には十分すぎるほど高い性能を持っています。
- 同期 (Sync) の実行。同期ボタンを押すことで、BedrockがS3のソースを読み込んで、ベクトル化したデータをベクトルストア(今回はPinecone)に格納します。
作業が完了したら Pinecone のインデックスのダッシュボードを確認してみましょう。クエリが保存されたような内容が出力されているはずです。
(5) Lambda関数の実装
API Gatewayから呼び出すLambdaを作成しましょう。 以下はPythonで書いたLamdba関数になります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
import json
import boto3
import os
# クライアントの初期化は外側で行うと実行効率が上がります
client = boto3.client('bedrock-agent-runtime', region_name='us-east-1')
def lambda_handler(event, context):
# --- セキュリティ設定:許可するIPアドレス ---
ALLOWED_IP = "XXX.XXX.XXX.XXX"
# API Gateway から送信元IPを取得
source_ip = event.get('requestContext', {}).get('http', {}).get('sourceIp')
# IPアドレスが一致しない場合は 403 Forbidden を返す
if source_ip != ALLOWED_IP:
return {
'statusCode': 403,
'body': json.dumps({'error': f'Forbidden: Access denied from {source_ip}'}, ensure_ascii=False)
}
# 1. 設定値(環境変数から取得するようにします)
KB_ID = os.environ.get('KNOWLEDGE_BASE_ID')
MODEL_ARN = os.environ.get('MODEL_ARN')
# 2. リクエスト(API Gateway経由)から質問文を抽出
try:
body = json.loads(event.get('body', '{}'))
user_query = body.get('text', '')
except:
user_query = ""
if not user_query:
return {'statusCode': 400, 'body': json.dumps('質問が見つかりません')}
# 3. 強化型プロンプトテンプレート
prompt_template = (
"あなたは提供された資料の内容を正確に伝える専門のアシスタントです。"
"以下の【資料の内容】に基づいて、質問に回答してください。"
"\n\n【ルール】\n"
"1. 回答には必ず提供された資料の内容のみを使用してください。\n"
"2. 資料に答えが含まれていない場合は「該当する情報が見当たりませんでした」と答えてください。\n"
"3. **必ず日本語で**回答してください。"
"\n\n【資料の内容】\n$search_results$\n\n質問: $query$"
)
# 4. Bedrock 呼び出し
try:
response = client.retrieve_and_generate(
input={'text': user_query},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KB_ID,
'modelArn': MODEL_ARN,
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': prompt_template
}
}
}
}
)
answer = response['output']['text']
return {
'statusCode': 200,
'body': json.dumps({'text': answer}, ensure_ascii=False)
}
except Exception as e:
return {'statusCode': 500, 'body': json.dumps({'error': str(e)})}
ポイントはALLOWED_IP。関係者からのみAPI Gatewayにアクセスを実現するために最初にIPアドレス制限のロジックを入れています。 (7)で動作確認を行いますが、皆さんのPCのIPアドレスを入力してください。PCのIPアドレスはWindows(コマンドプロンプト、PowerShell),Mac(ターミナル)問わず、以下のコマンドで確認可能です。
curl ifconfig.io
KNOWLEDGE_BASE_IDはナレッジベース ID、MODEL_ARNは使用するモデル(Haiku)のURLを、環境変数で設定するようにしています。
作成したLambdaはデプロイするのを忘れずに!
(6) API Gatewayの設定
最後に、作成した Lambda 関数をインターネット経由で呼び出せるようにエンドポイント)を作ります。 AWS API Gateway には、高機能な「REST API」と、軽量・安価な「HTTP API」の 2 種類があります。今回は設定が非常にシンプルで、デフォルトで 「自動デプロイ(Auto-deploy)」 が有効になっている HTTP API を選択しました。
- API の作成
- API Gateway コンソールで「API を作成」を押し、「HTTP API」 の構築ボタンを選択します。API 名は bedrock-rag-api など、分かりやすい名前を付けます。
- API の作成
- ルート(Route)の設定
- メソッドを POST、パスを / に設定します。
- ルート(Route)の設定
- Lambda との統合(Integration)
- 手順(5)で作った Lambda 関数 を統合先として選択します。
- Lambda との統合(Integration)
作成ボタンを押した瞬間、「呼び出し URL」 が発行されます。左メニューの「デプロイ」を選択すると、デプロイ用URLが表示されています。
(7) 動作の確認
ここまで来ました、実際にAPI Gatewayにアクセスできることを確認してみましょう。
curl -X POST https://XXXXXXXXXX.execute-api.us-east-1.amazonaws.com/ -H "Content-Type: application/json" -d "{\"text\": \"社内資料に質問を投げてみましょう。回答が返ってきます\"}"
これで社内資料について回答してくれるAIチャットが出来上がりました。ここまで来たらあとはWebサーバ上でホスティングするもよし、S3にAPIを呼び出すjavascriptを記載したhtmlファイルを配置してアクセスするもよし、SlackやTeamsと連携するもよしです。ローカルでhtmlファイルからJavaScriptでAPIGatewayのARNを呼び出して使うこともできます。
・・・と思っていたんだよな。ここまで書いた記事を、1か月後もう一度動かそうとしたら、使っていたAIモデルが動かなくなり(Haiku 3.5が利用できなくなりました)、IAMロールの設定変更やLambdaのコードをいろいろ直すも呼び出すことができなくなり積みました。まさか1か月でプロダクトがゴミになるとは。AIの進化のスピードの速さを実感しました。
今回作成したインフラはAWS SAMを使ってIaC化しました。以下に公開しています。
https://github.com/Usek2g/bedrock-pinecone-chatbot