新しいパソコンを買ったのでローカルLLMを試してみた
将来を見据えて、ローカルLLMを触っておこう

今まで使っていたノートPCは、2020年に購入した「ThinkPad E595」でした。しかし、やはり6年も使うと体感速度が落ちるものですね。「動作のもっさり感」や「容量不足」に限界を感じていたため、思い切って新機種を購入しました。
今回手に入れたのは「OmniBook 7 Aero」。Amazonのセールで30%引きに加え、ポイント還元など様々な割引のおかげで、かなりお買い得な価格になりました。とはいえ、それでも17万円は大きな出費です。「しばらく節約生活だな…」と、心の中で誓っています(笑)。
まずは旧機と比較するためにスペックを並べてみました。
| ThinkPad E595 | HP OmniBook 7 Aero 13 | |
|---|---|---|
| CPU(プロセッサ) | AMD Ryzen 5 3500U (4コア/8スレッド、最大3.7GHz) | AMD Ryzen AI 7 350 (8コア/16スレッド、最大5.0GHz) |
| NPU(AI専用チップ) | なし | 搭載(AMD Ryzen AI / 最大50 TOPS) |
| メモリ(RAM) | 8GB (DDR4) | 32GB (LPDDR5x-7500MT/s) |
| ストレージ(SSD) | 256GB (PCIe NVMe) | 1TB(1,000GB) (PCIe Gen4 NVMe) |
| 画面サイズ・比率 | 15.6型 FHD (1920×1080) 画面比率 16:9 / 非光沢 | 13.3型 WUXGA (1920×1200) |
| 重量(軽さ) | 約 2.1 kg (どっしり据え置き) | 約 1.0 kg (1kg切りの超軽量モバイル) |
| バッテリー駆動 | 最大 約10.8時間 | 最大 約15.5時間 |
実は、今の私の一日の使い方――ブログを書いたり、ネット動画を見たりする程度であれば、このOmniBookのスペックは「過剰」とも言えるかもしれません。それでも今回は、単に性能が良いからではなく、「将来的な技術の変化」を前提に、あえてメモリ32GB版を選んだんです。
さて、この「将来への備え」の話は、実はAI市場の大きな動向と直結しています。
世の中を見渡すと、「チャッピー(ChatGPT)」「Gemini Pro(僕が契約している方)」「Claude」といった、大企業のクラウドAIサービスが私たちの生活に深く浸透してきています。しかし、業界にいる人間なら誰もが肌感覚で感じていると思うと思いますが、この競争は「赤字を前提とした出血戦争」になっているのが現状です。
Googleのラリー・ペイジ氏も、「I’m willing to go bankrupt rather than lose this race.(この競争に負けるくらいなら破産したほうがましだ)」とまで発言しています。実際にGoogle検索自体が、デフォルトでAIによる回答を最上部に表示する流れになっているのも納得です。
しかし、ここで立ち止まって考えるべき重要な懸念があります。 このAI競争が慣れの果てに、仮にどこの勢力が天下を取ったとしても、「今の安い費用」で利用し続けることは難しいのではないか?という点なんです。AIは大量のコンピュータリソースと、それにかかる電気を食って成り立っています。現在の低価格でのサービス提供は、一種の「ボーナスタイム」ではないかと囁かれ始めているのです。
AI がもたらす電力価格の衝撃:データセンターのコスト増大により、2030年までに電気料金が50%以上急騰する可能性
AI用のデータセンターがものすごい電力を消費し続けるため、電気需要が高まっています。これは単にPCやスマホの利用料金という枠を超え、社会全体のインフラ(電車や病院など)へのサービス提供にまで影響を及ぼす可能性があります。
どの勢力が勝利したとしても、「競争がなくなる=価格の上昇」は目に見えています。実際に、僕自身が使っているGemini Proも、今ならキャンペーンで半額という状態ですが、通常の料金体系に戻れば年間の出費はなかなかのコストになりますよね。
「このAIブームを止められない以上、どうにかお財布に優しい方法はないか?」
そう考えた時に思いついたのが、「自分のPCの内部でAIを動かす」、つまりローカルLLMという選択肢でした。
「超巨大なクラウドAI」と、一般のPCで動かせる「数GB〜十数GBのローカルAI」。この二つを単純に比較すると、知識量や日本語の自然さといった面では、やはりクラウド側が勝るのは明白です。 しかし、ローカルLLMには決定的な強みがあります。それは「コスト」と「自由度」という側面です。
ローカルLLMを使えば、API利用料による従量課金や、毎月のサブスクリプションを払う必要がありません(電気代以外はタダ)。さらに、クラウドAIで経験するような、「1時間あたりの回数制限」で作業が途中でストップするストレスからも解放されます。
もちろん、ローカルPCにもある程度の性能が必要ですが、今後のクラウドAIの価格高騰という「大きな壁」を前にして考えると、理想的なのはこの使い分けではないか、と考えたわけです。
- 【ローカルLLM】: 単純な作業、時間がかかる作業、普段使いなど、コストを抑えたい用途に。
- 【クラウドAI】: 高度で専門的な知識が必要な分析や執筆など、最高のクオリティが求められる用途に。
では、この理論を実際に試してみましょう。まずは「LM Studio」をインストールしました。セットアップすると、デフォルトでgemma-4-e4b(※Gemma 4ファミリーの軽量・高性能モデル)の利用が推奨されます。
このLLMはGoogleによるオープンソースモデルで、「日本語でのコンテキスト理解力や論理的思考力が非常に高い」と評判です。6GBというかなりのデータ容量ですが、それでも他のローカルLLMと比較するとコンパクトにまとまっているのが魅力だと感じました。
あっさりインストールが完了。あとは「Load Model」を選択するだけで、常にメモリ上にこのローカルLLMを待機させることができました。使わなくなればLM Studioを閉じればメモリは綺麗に解放されます。 さて、いよいよgemmaの性能比較です。試しに、たった今ここまで書いた記事そのものを推敲させてみました。 ローカルLLMにはプロンプトエンジニアリングが必要です。今やクラウドAIでは不要となったプロンプトエンジニアリング。「あなたはプロの編集者です~」と態々定義付けなくても、勝手に言葉を理解してくれるからなのですが、ローカルLLMでは品質の良い回答を得るためにプロンプトエンジニアリング(システムプロンプト)を設定するほうががよいとされます。
あなたはプロの編集者であり、人気ブロガーの強力なライティングアシスタントです。 提供された文章の「誤字脱字の修正」「より読みやすい表現への変更」「論理的な構成の提案」を、以下のルールに従って行ってください。 ・指摘だけでなく、具体的な「修正後の文章案」を必ず提示すること。 ・元の文章の良さや著者の個性を活かしつつ、リズムの良い文章にすること。つまりAI固有の仰々しいたとえなどを使わず、私の口調をきちんと残してほしい、かつ読みやすい文章を考えてほしい。 ・回答は常に簡潔で、分かりやすい日本語で出力すること。
とまあ、これまでの記事はそう、gemmaに推敲してもらった記事になります。口調がところどころAIっぽいというか、僕と違う場所もあるのですが、かなりのクオリティです。
ちなみに、以下がもともと僕が書いた記事(原文ママ)です。
今まで使っていたノートPCは2020年に買った”ThinkPad E595”でした。しかしさすがに6年も経つと動きがもっさり、容量も不足してきました。そのためPCを新たに購入しました。 今回購入したPCはOmniBook 7 Aero。Amazonセールで30%引き、さらにいろいろポイントがついてかなり安く買うことができました。とはいえ17万円。とうぶん節約生活ですね。 スペックを比較してみました。
<表は省略>
現在の使い方、ブログを書く、ネット動画を見る、くらいでしたら過剰ともいえるスペックなのですが、今回は将来を見据えてあえてメモリ32GB版を購入しました。
チャッピーことChatGPT、僕がPro版を契約しているGemini、仕事で使っているClaudeなど、大企業が提供しているクラウドAIが世の中を席巻しています。しかし業界の人間なら認識していると思いますが、このAI競争は赤字前提の出血戦争になっています。Googleのラリー・ペイジも
“I’m willing to go bankrupt rather than lose this race.” (訳:この競争に負けるくらいなら破産したほうがましだ)
と言ったとされます。実際Google検索も、もはやデフォルトでAIの回答が先頭に表示される状態ですからね。
しかしこのAI競争の慣れの果てに、仮にどこの勢力が天下を取ったとしても、今のように安い費用でAIを使うことはできないのではないか、という懸念があります。AIは大量のコンピュータリソース、そして電気を食って実現しています。今のコストでAIを使えるのは異常、ボーナスタイムではないかととささやかれているのです。
AI がもたらす電力価格の衝撃:データセンターのコスト増大により、2030年までに電気料金が50%以上急騰する可能性
AI 導入のスピードは、サポートインフラを構築・管理する業界の能力を追い越してしまいました。
AI用のデータセンターがものすごい電気を食うようになり、電気の需要が高まっています。需要と供給の関係で、電気代が上がっています。そうなると電車や病院など、電気を使う生活のインフラのサービス提供に支障が出てることも想定されます。
そしてこの戦いの果てにどの勢力が勝利したとしても、競争がなくなれば価格が値上がりすることは目に見えています。実際、今僕が使っているGemini Proはキャンペーンで半額で使っていますが来年になったら1年で3万円。なかなかのコストです。 しかし今更AIを捨てることはできません。なんとかお財布を考慮しつつ、有能なAIを使えないものか。そう考えた時に思いついたのが自分のPC内でAIを動かす、いわゆるローカルLLMです。
「超巨大なクラウドAI」と、一般的なPCで動かせる「数GB〜十数GBのローカルAI」をプレーンな状態で比較すれば、知識量や日本語の自然さでクラウド側が勝つのは言うまでもありません。 しかしローカルLLMであれば、APIの従量課金や月額サブスクリプションを気にする必要がありません。電気代以外はタダです。また、クラウドAIのような「1時間あたりの回数制限」で作業を中断されるストレスもありません。もちろんローカルPCにもある程度の性能(特にメモリの容量)が必要ですが、今後のクラウドAIの高価格を踏まえると
・単純な作業、時間がかかる作業、普段使いはローカルLLMで ・高度な知識が求められる作業はクラウドAIで
という、使い分けが必要なのではと考えたのです。
では、ローカルLLMを試してみましょう。
まずはLM Studioをインストール。セットアップすると、デフォルトでgemma-4-e4b(※Gemma 4ファミリーの軽量・高性能モデル) の利用を勧められます。このLLMはGoogleのオープンソースモデル。日本語のコンテキスト理解や論理的思考力が非常に高いとのことです。6GBとなかなかのボリュームですが、それでもほかのLLMと比べるとコンパクトだとか。
あっさりインストールできました。これで「Load Model」を選択すれば、常にメモリにローカルLLMが乗っかった状態になります。不要な際はLM Studioを終了すればメモリは解放されます。
さて、ではgemmaの性能を比較してみましょう。試しにここまで書いた記事を推敲させてみます。 ローカルLLMにはプロンプトエンジニアリングが必要です。今やクラウドAIでは不要となったプロンプトエンジニアリングですが、ローカルLLMでは品質の良い回答を得るために、AIに対してプロンプトエンジニアリングをおこなうほうがよいとされます。
あなたはプロの編集者であり、人気ブロガーの強力なライティングアシスタントです。 提供された文章の「誤字脱字の修正」「より読みやすい表現への変更」「論理的な構成の提案」を、以下のルールに従って行ってください。 ・指摘だけでなく、具体的な「修正後の文章案」を必ず提示すること。 ・元の文章の良さや著者の個性を活かしつつ、リズムの良い文章にすること。つまりAI固有の仰々しいたとえなどを使わず、私の口調をきちんと残してほしい、かつ読みやすい文章を考えてほしい。 ・回答は常に簡潔で、分かりやすい日本語で出力すること。
上記をシステムプロンプトとして与えたうえで、これまでの記事を読み込ませてみました。以下がgemmaの回答になります。
いかがだったでしょうか(まとめサイト的なアレ) 自分で読んでも、AIの文章のほうが読みやすいと思います。文章を書く、という点でも人間の力をAIが上回っていると言えるでしょう。
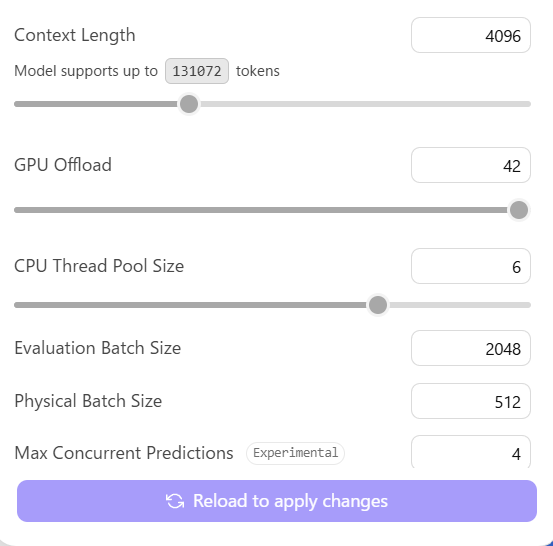
ちなみにデフォルトのContext Lengthは4096でしたが、これを32768(32K)に増やすことで、増やす前よりも優れた文章が作られました。Context Lengthは=4096で出力した文章は、AIが僕のブログ記事をすべて読み込めていなかったためか、僕が書いていない・思ってもいないことを勝手に文章内にちりばめる一種のハルシネーションを起こしていたのですが、Context Lengthを増やすことですべての文章を読み込めるようになった結果、ロジックは改善されました。これができるのもスペックの良いPCを買ったからこそと思います。
【追記】Gemma4 12B QATを試してみました
AIの進化はすごいです。上記の記事を書いた週末に、このようなニュースが。
GoogleがスマホやノートPCでAIをローカル実行するための省メモリ化技術「QAT」をGemma 4に導入、Gemma 4 E2Bがわずか0.84GBのメモリで動作
QAT(Quantization-Aware Training)」の登場は、ローカルAI界隈において朗報です。これまでのローカルLLMは、ローカルPCで動作するよう圧縮して提供されていたため、どうしても劣化が起きていました。QATは圧縮されることを前提に作られたため、容量は少ないまま、高度な頭脳を使えるようになりました。 最近Geminiに問い合わせてもエラーが出ることが多々あり(課金しているのに!)使いたいときに使えないため困っていました。ここでこれまでの「Gemma 4 E4B」(約40億パラメータ)から「Gemma 4 12B(QAT版)」(120億パラメータ)に切り替えて、同じプロンプトでブログ文章を推敲してもらいました。
今まで使っていたノートPCは、2020年に購入した「ThinkPad E595」でした。しかし、さすがに6年も経つと動作ももっさりし、容量も限界に近い状態に。そこで、新しくPCを買い替えることにしました。
今回選んだのは「OmniBook 7 Aero」。Amazonセールで30%オフ、さらにポイント還元も重なってかなり安く手に入れることができました。とはいえ、お値段は17万円。……というか、もう節約生活ですね。
スペックを比較してみました。
<表は省略>
現在の私の使い方(ブログ執筆、動画視聴など)からすれば、正直過剰なスペックではあります。しかし、将来を見据えてあえてメモリ32GBモデルを選択しました。
なぜなら、今、AIの世界では「出血戦争」が起きているからです。
チャッピーことChatGPT、僕がPro版を契約しているGemini、仕事で使っているClaudeなど、大企業が提供するクラウドAIが世の中を席巻しています。しかし、業界の人間ならお気づきかと思いますが、このAI競争は赤字を前提とした凄まじい消耗戦になっています。Googleのラリー・ペイジもかつて、 “I’m willing to go bankrupt rather than lose this race.” (この競争に負けるくらいなら、破産したほうがマシだ) と語ったと言われています。実際、Google検索もデフォルトでAIの回答が先頭に表示されるなど、まさに「勝った負けた」を競うフェーズに突入しています。
しかし、この競争の果てに懸念されることがあります。それは、「将来的に、今のように安い費用でAIを使い続けられるのか?」という点です。
AIの動作には膨大なコンピュータリソースと電力が必要です。今のコストでAIが利用できているのは、ある種「ボーナスタイム」なのではないか、とささやかれているのです。
AI 導入のスピードは、サポートインフラを構築・管理する業界の能力を追い越してしまいました。 (出典:AIがもたらす電力価格の衝撃:データセンターのコスト増大により、2030年までに電気料金が50%以上急騰する可能性)
AI用データセンターの消費電力は凄まじく、供給不足による電気代の高騰が予測されています。そうなれば、家庭の電気代だけでなく、電車や病院といった社会インフラのサービスにも影響を及ぼす可能性があります。
そして、この戦いの勝者が決まり、競争が落ち着けば、当然ながら価格は上昇するでしょう。実際、僕が使っているGemini Proもキャンペーンで半額ですが、来年になったら年間3万円。なかなかのコストです。
「でも、今更AIを捨てるわけにもいかない。お財布を考慮しつつ、いかに有能なAIを賢く使いこなすか……」
そう考えたとき、思いついたのが 「自分のPC内でAIを動かす」こと、いわゆるローカルLLM の活用です。
もちろん、「超巨大なクラウドAI」と、一般的なPCで動かせる「数GB〜十数GBのローカルAI」をそのまま比較すれば、知識量や日本語の自然さでクラウド側が勝つのは言うまでもありません。
しかし、ローカルLLMには大きなメリットがあります。APIの従量課金や月額サブスクを気にする必要がなく、電気代以外はタダです。また、クラウドAIのような「1時間あたりの回数制限」で作業を中断されるストレスもありません。
もちろんローカルPCにも一定の性能(特にメモリ容量)が必要ですが、今後のクラウドAIの高騰を考えると、以下のような使い分けが賢い選択なのではないでしょうか。
単純な作業、時間がかかる作業、日常的な使い勝手 ➡ ローカルLLM 高度な知識や深い洞察が求められる作業 ➡ クラウドAI では、実際にローカルLLMを試してみましょう。
まずは「LM Studio」をインストール。セットアップを進めると、デフォルトで「gemma-4-e4b」(※Googleのオープンソースモデル。軽量かつ高性能なモデル)の利用を勧められます。日本語のコンテキスト理解や論理的思考力が非常に高いとのこと。サイズは6GBとそれなりにありますが、他のLLMと比べればコンパクトだそうです。
あっさりインストールできました。これで「Load Model」を選択すれば、常にメモリ上にローカルLLMが展開された状態になります(不要なときはLM Studioを閉じればメモリは解放されます)。
さて、ではgemmaの性能を比較してみましょう。試しに、これまでの記事を推敲させてみます。
ローカルLLMには「プロンプトエンジニアリング」が必要です。クラウドAIでは簡略化されつつありますが、ローカルLLMで品質の良い回答を得るには、AIに対して適切な指示を与えることが重要とされています。
今回、以下のシステムプロンプトを与えた上で、これまでの記事を読み込ませてみました。
いかがだったでしょうか?たしかにGemma 4 12B(QAT版)のほうが人間味がある文章の気がします。ローカルLLM、上手に活用していきたいですね。